
Motivation
I’m not a fan of Microsoft’s Language Integrated Query (LINQ). But ranting about a language feature is an ineffective way to convince programmers of the merits of other techniques. So decided to construct a detailed example that illustrates how LINQ solves a certain problem, contrast it with a different technique, then highlight the deficiencies of LINQ and extol the virtues of my preferred technique.
I happily set about creating a relational database and C# object model, then hit an impasse. When the time came to determine how to write LINQ code that maps the relational data into the C# object model, I found myself reluctant to do it. And I realized that’s exactly my gripe with LINQ.
I don’t want to write Object / Relational Mapping (ORM) code using LINQ because I already know how to do it simply, efficiently, and obviously without LINQ.
LINQ’s Shortcomings
- LINQ doesn’t eliminate a learning curve- it introduces its own.
- LINQ doesn’t clarify how data is acquired and related. Its syntactic sugar shrouds it in mystery.
- LINQ doesn’t simplify the Object / Relational Mapping problem.
- LINQ allocates too much memory. The memory must be garbage-collected by the runtime, degrading performance.
- LINQ makes it difficult to reason about the performance of data acquisition code.
- It’s not immediately obvious when LINQ will filter an expression tree versus instantiating C# objects, then filtering.
- It’s not immediately obvious when LINQ will join data server-side versus downloading data to the client, then joining.
- It’s no simpler to write a LINQ query than it is to write a SQL query with a Micro ORM such as Dapper.
- Most importantly, alternatives like Dapper expose the power, flexibility, and speed of SQL.
Earlier, I said I know how to do ORM simply, efficiently, and obviously without LINQ. By “simply” I mean my code is terse yet understandable. By “efficiently” I mean my code executes fast and uses memory sparingly. By “obviously” I mean my code expresses design intent, which is helpful for programmers who maintain the code.
LINQ hides SQL from the developer. I have a lot of respect for Anders Hejlsberg, the designer of C# and architect of LINQ. But when Hejlsberg and his fellow architects decided to solve the ORM problem by hiding SQL behind expression trees, they made the mistake of being too clever. Why? Because…
The best Domain-Specific Language (DSL) for manipulating data is Structured Query Language (SQL).
Goal
I’ll show you my preferred ORM technique for mapping data from a relational database to a C# object model. To convince you this technique is robust enough for enterprise development, I’ll use it on a server to construct a complex object graph with cyclical references, serialize it as JSON, transmit it across my localhost network to a client, then deserialize it back into an object graph on the client with all references retained. I’ll do this for 5,400 objects extracted from a database containing a million items in less than 150 milliseconds. That’s end-to-end, cross-server acquisition of a large, cyclical object graph in < 150ms, leaving plenty of time to render an HTML view (which I won’t do in this demo) and still deliver a sub-second experience for the user. Hell, sub-half-second.
That’s end-to-end, cross-server acquisition of a large, cyclical object graph in < 150ms.
The code I write will be self-documenting. It will clearly explain…
- How the data is retrieved from a database.
- How the data is mapped to C# objects.
- How the objects are related.
I’ll write example code inspired by an application I wrote for my employer. I’ll simplify it so we can focus on the ORM problem, though the database tables and C# classes I describe are similar to their real-world counterparts.
Application
I wrote a web application that places markers on a Google Map that represent a) customers with open service calls and b) the last known location (via TripLog) of service technicians. The map is used by dispatchers whose job it is to route service technicians to customers who own machines needing repair. Markers are color-coded to convey various information depending on the view selected. In one view, the color of the marker represents a technician (each technician is assigned their own color). This enables dispatchers, with a quick glance and a couple clicks, to ensure all of an individual technician’s daily calls are clustered geographically to minimize the technician’s commute time and maximize the number of calls they can complete that day.
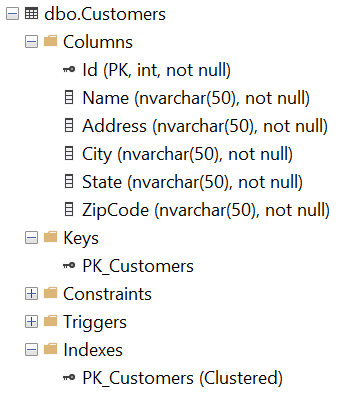
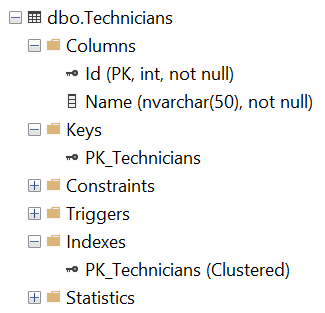
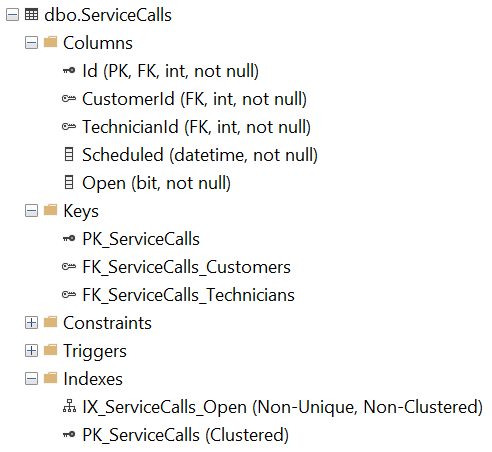
Database Schema
The database schema consists of a Customers table, a Technicians table, and a ServiceCalls table. The ServiceCalls table refers to the first two tables via foreign keys. Indices are added to all three tables to improve query performance. Only the indices necessary for this demo are added.
 |
 |
 |
|
Let’s create the database.
Let’s populate the database with semi-random data. We’ll shape the data to represent a typical technician workload of four to eight service calls per day. We’ll include a year’s worth of data with all of today’s scheduled calls marked open, most but not all of yesterday’s calls marked closed, and all older calls marked closed.
I ran the above script and program. They created a database and inserted 1,094,964 rows into the ServiceCalls table.
C# Object Model
Let’s create an object model with many cyclical references. I do not include cyclical references merely to foil a junior programmer. The references serve a few purposes.
- Cyclical references provide many pathways through the data, giving web programmers flexibility to meet changing user interface requirements.
- Cyclical references reduce the amount of data transferred from the service (via JSON) to the website.
- Cyclical references eliminate a subtle counting bug after an object graph passes through JSON serialization / deserialization.
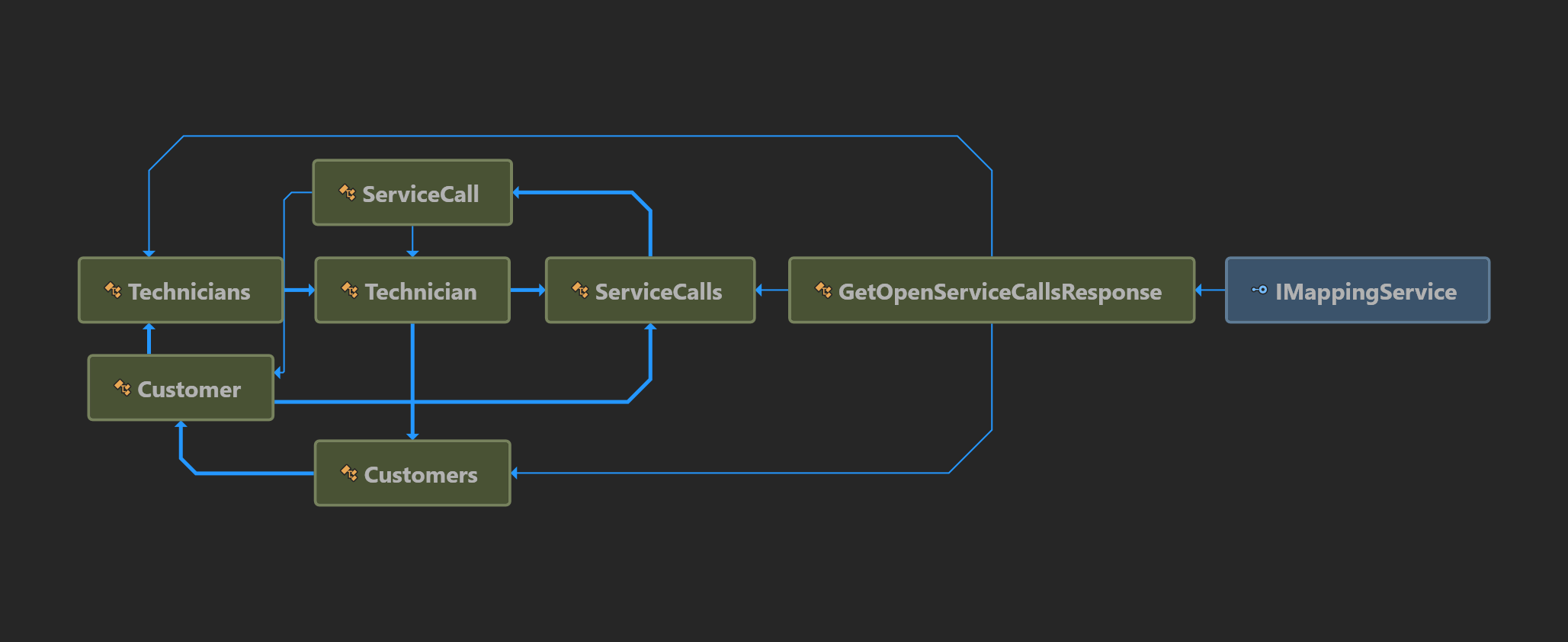
Refer to my Dapper Contract project in GitHub for details. Basically, the Technician is at the center of this model. A Technician has a collection of Customers and ServiceCalls. A Customer has a collection of Technicians (a large hospital may have many onsite) and ServiceCalls. A ServiceCall refers to a Technician and a Customer.
When writing the mapping application for my employer I stumbled across the counting bug I mentioned above. Not a bug so much as a design choice: By default, Json.NET does not preserve object references. It recursively writes all object properties to the JSON text stream. So if a ServiceCall refers to a Technician, and a Technician has a collection of ServiceCalls, the ServiceCalls in that collection will refer back to the Technician. The recursive serialization logic will follow these circular references endlessly, inflating the size of the JSON message until memory is exhausted and the .NET runtime throws a StackOverflowException.
The problem can be solved in two ways: 1) change the object model so objects don’t refer to each other in a circular manner- use integer IDs instead. Or 2) set PreserveReferencesHandling = PreserveReferencesHandling.All. The first option shifts responsibility for counting from the server to the client (the website code). For example, to determine how many service calls John Doe is assigned, we can’t rely on technician.ServiceCalls.Count. It will always equal 1 because serialization will create multiple, independent copies of the “John Doe” Technician object. Obviously, the second option is a simpler solution. In one line of code we shift responsibility for tracking object references from our code to the Json.NET code. It’s free, as in beer.
WebAPI Service Method
Now the moment of truth. How to retrieve all open service calls for all technicians? As I mentioned earlier, the service calls can be plotted on a Google Map to aid a team of dispatchers who route technicians to customers who own machines needing repair. How do I retrieve this data without using LINQ? I write a SQL query then map its results to our C# object model using Dapper. Like this:
Dapper adds extension methods to the SqlConnection class. In the above code, I use the QueryAsync<TFirst, TSecond, TThird, TReturn> extension method, which is called for each row Dapper encounters while iterating over the SQL query results. I wrote a SQL query that joins service call, customer, and technician data on each row in the results. I provide my SQL query and a lambda method as parameters to the generic QueryAsync method. In the lambda method, I configure relationships among objects- sometimes referring to an object created by Dapper (it creates one ServiceCall, Customer, and Technician per row); other times referring to an object stored in a collection. Dapper, by default, splits on columns named “Id” (though this is configurable), first setting properties on type TFirst, then type TSecond after encountering a column named “Id”, then type TThird after encountering another column named “Id”, etc. Dapper calls this feature Multi Mapping.
Because Dapper allocates one ServiceCall, Customer, and Technician object per row, and sometimes I immediately discard a Customer or Technician object because I already have an instance of it in a collection, some memory is wasted and must be garbage-collected. However, this is a minor price to pay for the convenience of a) writing my own SQL and b) consolidating all object mapping in a single method. Writing more memory-efficient code using an IDataReader passed to each class constructor would scatter the logic over many files. The Dapper code performs well, as you’ll see below.
As I mentioned above, be sure to instruct Json.NET to preserve object references in the Startup class of the WebAPI service. See Preserving Object References documentation on the Json.NET website for details.
Performance
To be entirely sure my performance measurements are not skewed by client-side HTTP caching, I wrote a CacheBustingMessageHandler that adds a GUID querystring parameter to all HTTP requests.
Then I wrote a Console application to act as a client calling the WebAPI service using a) an HttpClient + Json.NET or b) Refit (which internally uses the CacheBustingMessageHandler, HttpClient, and Json.NET). Refit generates strongly-typed REST service proxies. It’s a fantastic library. But this post is long enough already, so I’ll discuss Refit in a later post.
Let’s run the client application. After allowing the client to warm up (cache JSON to C# contracts), we observe the HttpClient and Refit proxies perform similarly. Both are very fast considering the amount of data they must deserialize and the complexity of the object graph they must reconstruct.
PS C:\Users\Erik\...\publish> .\ErikTheCoder.Sandbox.Dapper.Client.exe json.net Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.425 seconds. Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.136 seconds. Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.137 seconds. Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.125 seconds. PS C:\Users\Erik\...\publish> .\ErikTheCoder.Sandbox.Dapper.Client.exe refit Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.408 seconds. Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.123 seconds. Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.122 seconds. Retrieved 3045 service calls, 1857 customers, and 500 technicians in 0.127 seconds.
Fiddler traces confirm both the HttpClient and Refit generate unique URLs with each request. So they are not benefitting from client-side HTTP caching.

Preserving Object References
Fiddler traces also illustrate how Json.NET preserves object references. On the server, each object instance is assigned an $id number. (All the variables that begin with a dollar sign are assigned by Json.NET. They do not represent the names of any properties I defined in my classes.) If the same object instance (same location in memory) is encountered again via a circular reference, Json.NET adds a $ref number instead of writing the object instance’s properties to the JSON text stream. When Json.NET deserializes the JSON on the client (reading the JSON text stream and instantiating objects), if it encounters a $ref tag, it sets the object’s property to an existing object rather than instantiating a new one.
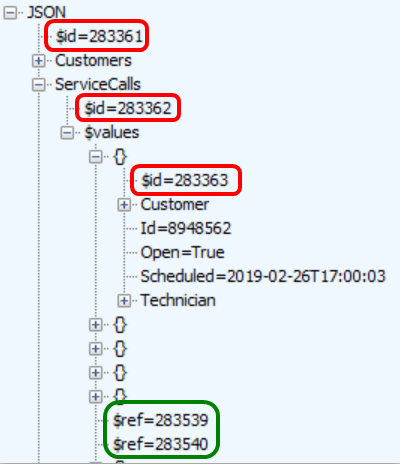
All the reference equality assertions in the client application pass.
Summary
Why use LINQ when the approach I detailed above is just as simple, gives the programmer greater control, and performs better?
SQL + Dapper + Refit == Performance + Design Intent + Ease of Use
Refer to the following projects in GitHub for details.
- Dapper Populate Database
- Dapper Contract
- Dapper Json Complex Object Graph (this is the WebAPI service)
- Dapper Client
