
Introduction
I have been reading Designing Data-Intensive Applications by Martin Kleppmann. (I heard of the book via a review Henrik Warne posted on his blog. I encourage you to read Henrik’s blog- excellent content, clearly articulated). I am only a third of the way through the book but can already say it is one of the best technical computer books I have ever read. As I said in a comment I left on Henrik’s blog, Martin Kleppmann has put a lot of effort into writing clearly and without pretension. He doesn’t use terms without defining the concepts behind them. And he doesn’t get lost in ivory-tower academic arguments. He stays focused on pragmatic concerns.
The technique of not using terms without first defining the concepts behind them is the correct way to write a technical book. (See Richard Feynman’s comments on the subject.) However, it makes for a dense treatise. So much so that a few weeks ago, having read chapter five on database replication, I decided to put down the book and investigate what I had learned.
Over the last three weeks I’ve probably spent a dozen hours- an hour here or there in the evening or on weekends- writing code to convince myself the algorithms Kleppmann describes actually work. I could have simply moved on to chapter six but I felt that would be hand-waving: You know, pretending to be smarter than I actually am, lying to myself that it’s all rather obvious, Q.E.D… adopting the intellectual dishonesty of a dilettante. No, I had to pause to write code that proves or disproves the claims Kleppmann had made.
My first challenge was scoping this research project. I wanted to write a demonstration program, then write a blog post about the program. However, Kleppmann discusses so many complex topics in chapter five alone, I could not write code to test everything he stated- I had to select one topic. I selected Leaderless Replication.
Leaderless Replication, being the most elaborate replication architecture described by Kleppmann- providing the most benefits- is the topic that fascinates me the most. It offers an opportunity to write some highly concurrent, asynchronous code.
I am proud to say my code works. It’s pretty cool. But before we get into the code, I should explain my choice of photo for this blog post. I stumbled on the idea accidentally. I was browsing Facebook and saw an ad by ESPN about their upcoming ten part documentary series on the 1990s Chicago Bulls. I have lived in Chicagoland my entire life. I have fond memories of watching Michael Jordan lead the Bulls to six championships in eight years. I thought to myself, how would basketball fans answer the question, “Which team is the current NBA champion?” They’d answer, “The Golden State Warriors.” Actually, it’s the Toronto Raptors. Shows how little I’ve watched the NBA since Jordan retired. What if you asked that question of a fan who fell into a coma in 1998 and woke up today? They’d answer, “The Chicago Bulls.”
How is this related to distributed computing? Well, no application under heavy load (think Facebook or Twitter) can possibly run off a single computer. Multiple computers must be used to respond to tens of thousands of requests per second. For globally popular web applications (again, Facebook or Twitter), these computers are distributed across the planet to decrease the physical distance (and network latency) between users and servers. It makes no sense to distribute web servers yet funnel all requests to a single database server- so database replicas also are distributed across the planet. If one of these databases goes offline- perhaps due to a hardware failure or system maintenance- when it comes back online it will have an outdated, incorrect view of the world. Why? Because while it was offline users were adding and changing content in the databases. This is similar to our sports fan above, who fell into a coma in 1998, wakes up in 2019, and thinks the Chicago Bulls are the reigning NBA champions.
The Problem
In order to reach the scale achieved by Facebook, Twitter, Amazon et al… a web application must be engineered to have the following characteristics.
- High Performance: The website must respond quickly to all requests, especially reads. On a typical website the ratio of read requests to write requests at any given moment is 100-to-1 or more.
- Fault Tolerance: The website must remain running (and responding to user requests) even if one or many of its servers crash or are taken offline for maintenance.
- Data Consistency: The website must return the same response to all users who ask the same question at the same moment. This is the same view of the world I mentioned in my NBA champion analogy above. In more pragmatic terms, when a popular singer announces their new album on Facebook, all users who visit the artist’s page immediately after the artist clicks the Post button- whether the user is in Los Angeles, Chicago, New York, London, Munich, Beijing (ignoring censorship), Singapore, Tokyo, Sydney, etc- should see the album announcement and not a photo of the artist’s cat, posted last week.
Well, it’s very difficult to engineer a distributed (meaning made of multiple, networked computers) application that provides all three guarantees. Probably impossible. Similar to the Heisenberg Uncertainty Principle in physics (that states one cannot precisely know both the position and momentum of a particle), the CAP Theorem in computer science states one can provide any two of the guarantees, but not all three. There is an intrinsic fuzziness- or granularity- to the material universe and the digital universe.
With regards to guarantee #3, we’ll settle for Eventual Consistency. I’ll explain later.
Comparison to Other Replication Architectures
This blog post is long enough without going into details of other replication strategies. If you want to know more about them, read the book. I’ll summarize a few:
- Leader and Follower: Clients (a user on their phone / PC, other applications, admin scripts, etc) read data from any server in the network (henceforth known as a node in distributed computing parlance). A load balancer device routes client requests to any node (randomly, round-robin, sticky sessions, etc) but all write requests must be routed to the leader node. All other nodes are known as followers. When the leader node receives a write, it updates its database, then informs its follower nodes of the new data. This can be done synchronously (waiting for followers to acknowledge they successfully updated their databases before responding to the client) or asynchronously (responding to the client immediately after updating the leader’s database but not waiting for followers to respond).
- Leader and Follower with Failover: The same algorithm as above but with additional code that automatically selects a new leader should the leader node go offline.
- Multi-Leader Replication: Clients never read or write to nodes outside their region. They read from any node in their region, but must write to the leader node in their region. This is useful for global deployments, where a leader is configured in each geographic region, perhaps in each data center. However it adds complexity, specifically with regard to write conflicts. Simultaneous edits of the same item by two users in two different geographic regions cause each regional leader to “think” it has the most up-to-date value of the item. It broadcasts the write to its follower nodes and the other regional leader nodes. It’s possible for one leader’s writes to “win” (overwriting all of the other leader’s writes) or for two different values to exist for the same item across the global databases.
- Multi-Leader Replication Topology: Multi-Leader architectures can be configured in a circular network (each leader node broadcasts only to one other leader node), a star network (each leader node broadcasts only to the supreme leader node, which then broadcasts to all other leader nodes), or an all-to-all network (each leader node broadcasts to all other leader nodes).
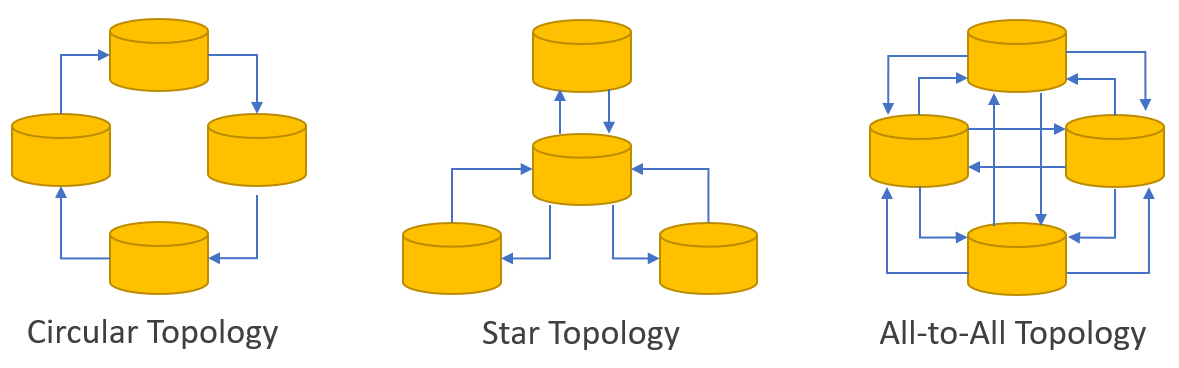
The main problem with these architectures is the leader node(s) becomes a bottleneck, both in terms of its ability to write data quickly enough and the network’s ability to route requests to it. The throughput of the entire system suffers. If you’re a user located in Las Vegas writing data to a leader node located in San Francisco, the operation may complete quickly. But if you’re a user located in London writing data to the same leader node in San Francisco, you have to wait for the data to travel all the way around the planet to a database in San Francisco. Then wait for an acknowledgment message to travel all the way around the planet back to London. Worse, if you refresh the page you just updated, you may see an old version prior to your edit because the leader server has not yet replicated the edit data to follower servers in London. You may mistakenly think your edit was unsuccessful and edit the page again, compounding the problem of laggy data- that is, data not yet visible due to network latency.
You may notice distributed computing nodes’ conflicting views of the current state of the (digital) world is similar to the concept of simultaneity from Einstein’s theory of relativity in physics. The most famous Gedankenexperimente being two lightning bolts simultaneously striking two ends of a moving railroad car. But I digress…
Leaderless Replication Algorithm
OK, so how can we improve the above replication architectures? By carefully controlling which clients are allowed to communicate with which nodes, deciding which I/O operations will be synchronous and which will be asynchronous, and leveraging a voting technique called quorums to resolve write conflicts (nodes disagreeing on the current value of an item). Here’s the algorithm in plain English:
- Determine the geographic region of all clients.
- Load-balance client requests (reads and writes) to nodes in the same region. Clients never read or write to nodes in other regions. This ensures client reads and writes perform well because the client is geographically close to the server.
- Broadcast writes to all global nodes. That is, a client writes to a regional node, which in turn broadcasts the write to all global nodes. However, wait only for all regional nodes to acknowledge a write (or throw an I/O exception) before responding to the client. This ensures high latency global connections (such as Chicago to London) do not adversely affect regional requests (such as Chicago to Milwaukee).
- When reading data, the node contacted by the client (concurrently) forwards the read request to all other regional nodes. Tally votes as the regional nodes respond. Once a quorum is reached (a majority of nodes agree on the answer to the request), respond to the client. This ensures a node that was offline for a long time, and only recently came back online (the Chicago Bulls fan in my basketball analogy above), cannot pollute answers to read requests with stale data. That is unless a catastrophe occurs- more than half the regional servers are offline simultaneously. If regional servers are placed in separate cities (or at least separate data centers or separate buildings) this significantly decreases the likelihood of a natural disaster (tornado, hurricane, flood, earthquake, etc) disrupting proper functioning of the web application.
- Optionally, if a node detects one or more of its sibling regional nodes has provided an incorrect answer to a request, update the incorrect nodes with the correct value. This is known as Read Repair. Read Repair provides guarantee #3, Eventual Consistency. In my basketball analogy, this is equivalent to a fan who’s been conscious since the 1990s discretely walking over to the fan who miraculously recovered from a coma and saying, “Listen, I love Michael Jordan’s Bulls as much as you do. But if someone asks you who is the current NBA champion, the correct answer is the Toronto Raptors. Oh, and we don’t access the Internet by dialing a land-line phone into AOL anymore. You’re welcome.”
Why use quorum voting? Two reasons: 1) As discussed above, to prevent data corruption when a down server comes back online. 2) More fundamentally, because broadcasting writes is a highly asynchronous, non-deterministic operation. Packet Switching networks, such as the Internet, cannot guarantee data sent across long distances to multiple servers (near to each other) follows the same path, let alone arrives at the same time. Therefore, it’s likely (at least for a short duration) that servers within a region hold different values for the same item.
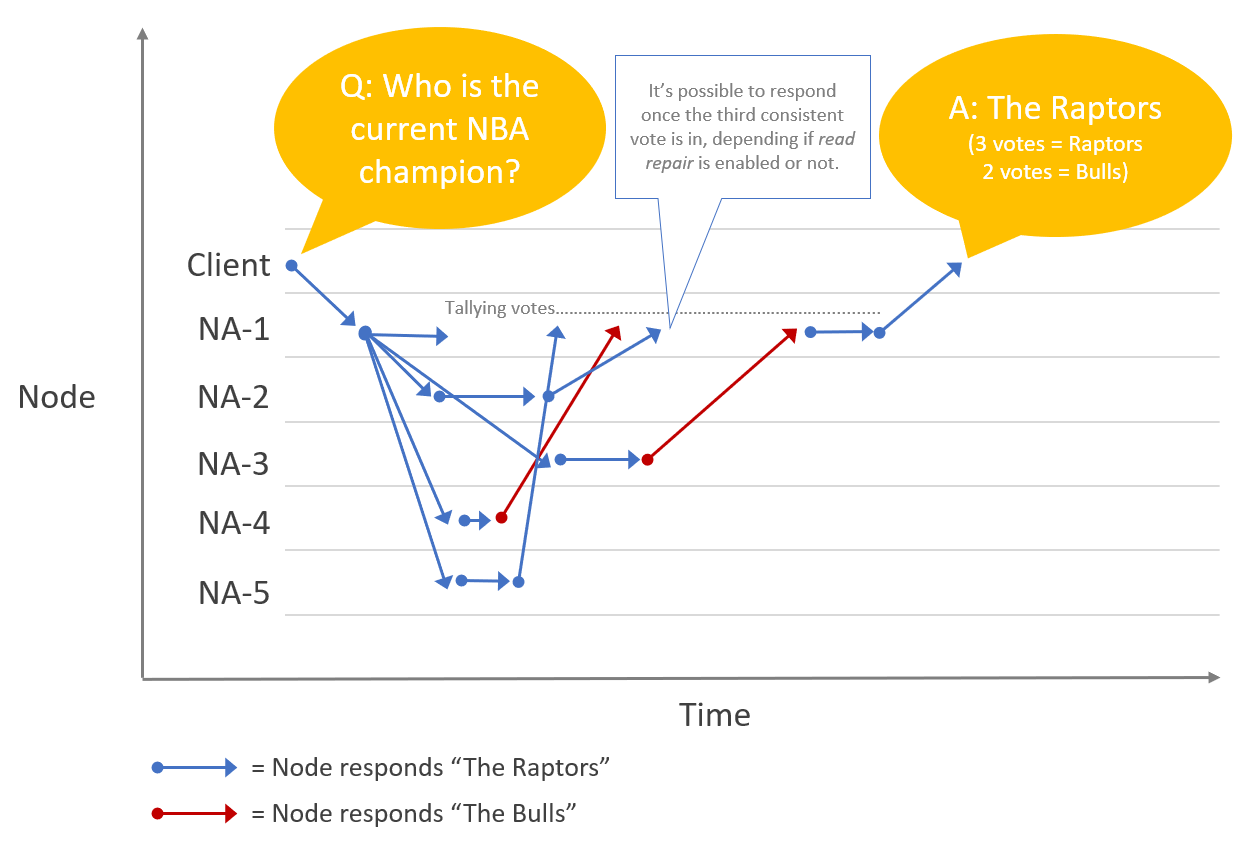
The diagram below illustrates the sequence of events (Read Repair not shown) for a read request in the Leaderless Replication algorithm. The client’s load balancer randomly selects the NA-1 node; the client asks NA-1 “Who is the current NBA champion?”; NA-1 forwards the request to the other North American nodes; three of the nodes respond “The Raptors”; Two of the nodes respond “The Bulls”; The NA-1 node counts the votes, determines the correct answer by quorum, and responds to the client, “The Raptors”. Note the latency of requests and responses vary per node. NA-5 is quick to respond. NA-3 is slow.
Leaderless Replication Code
Alright, enough exposition. Let’s write some code. First, a node. Rather than persisting data to a database (via a SQL insert or update statement), we’ll simulate persistence by storing key / value pairs in memory. We’ll use a ConcurrentDictionary so the data structure is thread-safe for simultaneous access by multiple threads (other nodes). We must provide pairs of read and write methods. For reads, one method that simply returns a key’s value and another method that forwards read requests to all other regional nodes and contains the quorum vote tallying logic. Why? Because if a read request causes a node to query all other regional nodes, which in turn query all other regional nodes, which in turn… we’d start an infinite loop of reads that would never respond to the client. Same reason for write requests (avoiding infinite broadcast loops). The abstract NodeBase class:
The QuorumNode class:
Let’s write a Connection class that simulates network latency via await Task.Delay(timeSpan).
Let’s use a two dimensional array to define latency between twenty global nodes, five each in four regions (North America, South America, Europe, and Asia). The matrix is dizzying. Simply put, connections among nodes in the same region are fast (responding in 10 – 50 milliseconds). Connections among nodes in disparate regions are slower, with South America to Asia being especially slow (responding in 500 – 999 milliseconds). Nodes do not connect to themselves- represented by a latency of 000 milliseconds.
Let’s write a Client class that uses Connection class instances to communicate with nodes in its region. Note the class load-balances requests to nodes by shuffling connections before asynchronously invoking methods over them. So, for example, the first time a client method is called it may invoke connections to nodes 3, 1, 4, 2, 5. The next time to nodes 5, 4, 2, 1, 3, etc. Also note if a connection fails (the node is offline) the client invokes the same method on the next connection (to a different regional node), if it fails, the next, etc… until it receives a response or is forced to throw an exception.
Let’s setup our global network.
Test Results
Guarantee #1 : High Performance
Now the moment of truth. Let’s test the guarantees the Leaderless Replication algorithm claims to provide. First, high performance. Let’s validate North American client reads are faster than reading across a high latency connection such as Asia to North America.
Running the program confirms this is indeed so.
PS C:\Users\Erik\...\Sandbox\Leaderless Replication> dotnet run -c release -- testreadperformance
Testing performance of North American client.
Writing sentinel value... done.
Wrote sentinel value in 0.167 seconds.
Reading sentinel value... done.
Sentinel value = Yada, yada, yada.
Read sentinel value in 0.115 seconds.
Testing performance of connection between Asian node and North American node.
Reading sentinel value... done.
Sentinel value = Yada, yada, yada.
Read sentinel value in 0.792 seconds.
Test result: success.
Guarantee #2 : Fault Tolerance
Next, fault tolerance. Let’s validate two of five nodes can be offline and yet read requests function correctly. Remember, a quorum of three votes are required to respond to client requests. Because three nodes remain online, this requirement is met. Let’s take a third node offline and validate a QuorumNotReachedException is thrown.
Running the program confirms these tests pass.
PS C:\Users\Erik\...\Sandbox\Leaderless Replication> dotnet run -c release -- testfaulttolerance Testing fault tolerance of North American nodes. Writing sentinel value... done. Wrote sentinel value in 0.140 seconds. Reading sentinel value... done. Sentinel value = Yada, yada, yada. Read sentinel value in 0.122 seconds. Taking two (of five) nodes offline... done. Reading sentinel value... done. Sentinel value = Yada, yada, yada. Read sentinel value in 0.151 seconds. Taking a third (of five) node offline... done. Reading sentinel value...Exception Type = ErikTheCoder.Sandbox.LeaderlessReplication.QuorumNotReachedException Exception Message = Exception of type 'ErikTheCoder.Sandbox.LeaderlessReplication.QuorumNotReachedException' was thrown. Exception StackTrace = at ErikTheCoder.Sandbox.LeaderlessReplication.QuorumNode.ReadValueAsync(String Key) at ErikTheCoder.Sandbox.LeaderlessReplication.Connection.ReadValueAsync(String Key) in C:\Users\Erik\Documents\Visual Studio 2019\Projects\Sandbox\Leaderless Replication\Connection.cs:line 35 at ErikTheCoder.Sandbox.LeaderlessReplication.Client.ReadValueAsync(String Key) in C:\Users\Erik\Documents\Visual Studio 2019\Projects\Sandbox\Leaderless Replication\Client.cs:line 25 at ErikTheCoder.Sandbox.LeaderlessReplication.Program.TestFaultTolerance(Client NaClient, Region NaRegion) in C:\Users\Erik\Documents\Visual Studio 2019\Projects\Sandbox\Leaderless Replication\Program.cs:line 186Test result: success.
Guarantee #3 : Data Consistency
Finally, data consistency. Let’s enable Read Repair and examine the state of the world (the value of each node’s sentinel key) when all nodes are online, when two nodes are offline, and when those two nodes come back online. Let’s validate writes are indeed broadcast to global nodes. Let’s validate two nodes have an outdated value for the sentinel key immediately after coming back online. And let’s validate eventually (wait one second) those two nodes have the correct value for the sentinel key.
Running the program confirms these tests pass.
PS C:\Users\Erik\...\Projects\Sandbox\Leaderless Replication> dotnet run -c release -- testeventualconsistency
Testing eventual consistency of global nodes.
Writing sentinel value... done.
Wrote sentinel value in 0.104 seconds.
Waiting for write to complete globally... done.
Reading sentinel value... done.
Sentinel value = Before.
Read sentinel value in 0.139 seconds.
Taking two (of five) nodes offline... done.
Updating sentinel value... done.
Wrote sentinel value in 0.240 seconds.
Waiting for write to complete globally... done.
NA-1 node's Sentinel Key = After.
NA-2 node's Sentinel Key = After.
NA-3 node's Sentinel Key = Before.
NA-4 node's Sentinel Key = Before.
NA-5 node's Sentinel Key = After.
SA-1 node's Sentinel Key = After.
SA-2 node's Sentinel Key = After.
SA-3 node's Sentinel Key = After.
SA-4 node's Sentinel Key = After.
SA-5 node's Sentinel Key = After.
EU-1 node's Sentinel Key = After.
EU-2 node's Sentinel Key = After.
EU-3 node's Sentinel Key = After.
EU-4 node's Sentinel Key = After.
EU-5 node's Sentinel Key = After.
AS-1 node's Sentinel Key = After.
AS-2 node's Sentinel Key = After.
AS-3 node's Sentinel Key = After.
AS-4 node's Sentinel Key = After.
AS-5 node's Sentinel Key = After.
Triggering read repairs by reading sentinel value again... done.
Read is done. However, read repairs are in progress.
Sentinel value = After.
Read sentinel value in 0.102 seconds.
NA-1 node's Sentinel Key = After.
NA-2 node's Sentinel Key = After.
NA-3 node's Sentinel Key = Before.
NA-4 node's Sentinel Key = Before.
NA-5 node's Sentinel Key = After.
SA-1 node's Sentinel Key = After.
SA-2 node's Sentinel Key = After.
SA-3 node's Sentinel Key = After.
SA-4 node's Sentinel Key = After.
SA-5 node's Sentinel Key = After.
EU-1 node's Sentinel Key = After.
EU-2 node's Sentinel Key = After.
EU-3 node's Sentinel Key = After.
EU-4 node's Sentinel Key = After.
EU-5 node's Sentinel Key = After.
AS-1 node's Sentinel Key = After.
AS-2 node's Sentinel Key = After.
AS-3 node's Sentinel Key = After.
AS-4 node's Sentinel Key = After.
AS-5 node's Sentinel Key = After.
Waiting for read repairs to complete... done.
NA-1 node's Sentinel Key = After.
NA-2 node's Sentinel Key = After.
NA-3 node's Sentinel Key = After.
NA-4 node's Sentinel Key = After.
NA-5 node's Sentinel Key = After.
SA-1 node's Sentinel Key = After.
SA-2 node's Sentinel Key = After.
SA-3 node's Sentinel Key = After.
SA-4 node's Sentinel Key = After.
SA-5 node's Sentinel Key = After.
EU-1 node's Sentinel Key = After.
EU-2 node's Sentinel Key = After.
EU-3 node's Sentinel Key = After.
EU-4 node's Sentinel Key = After.
EU-5 node's Sentinel Key = After.
AS-1 node's Sentinel Key = After.
AS-2 node's Sentinel Key = After.
AS-3 node's Sentinel Key = After.
AS-4 node's Sentinel Key = After.
AS-5 node's Sentinel Key = After.
Test result: success.
If we disable Read Repair (pass false as the final parameter when creating nodes), the tests fail as expected.
QuorumNode node = new QuorumNode(_random, ++Id, $"{RegionName}-{RegionalNodes.Count + 1}", RegionName, requiredVotes, false);
Waiting for read repairs to complete... done.
NA-1 node's Sentinel Key = After.
NA-2 node's Sentinel Key = After.
NA-3 node's Sentinel Key = Before.
NA-4 node's Sentinel Key = Before.
NA-5 node's Sentinel Key = After.
SA-1 node's Sentinel Key = After.
SA-2 node's Sentinel Key = After.
SA-3 node's Sentinel Key = After.
SA-4 node's Sentinel Key = After.
SA-5 node's Sentinel Key = After.
EU-1 node's Sentinel Key = After.
EU-2 node's Sentinel Key = After.
EU-3 node's Sentinel Key = After.
EU-4 node's Sentinel Key = After.
EU-5 node's Sentinel Key = After.
AS-1 node's Sentinel Key = After.
AS-2 node's Sentinel Key = After.
AS-3 node's Sentinel Key = After.
AS-4 node's Sentinel Key = After.
AS-5 node's Sentinel Key = After.
Test result: failure.
Conclusion
I hope you enjoyed this explanation of how large and popular websites are architected for high performance, fault tolerance, and data consistency. While reading Martin Kleppmann’s book, Designing Data-Intensive Applications, I had a hunch a few pages in chapter five represented a significant amount of intellectual effort and coding hours to validate. This research project confirmed it- and confirmed the Leaderless Replication algorithm functions correctly and does provide the three guarantees it claims to provide.
You may review the full source code in the Leaderless Replication folder of my Sandbox project in GitHub.
