In my previous post I mentioned I wrote what I call an async producer / consumer pipeline. I described in detail a compiler error I encountered in my initial efforts, and how I resolved the error, but did not share or discuss the actual pipeline code. I focused on how the VB language, generally regarded as less capable and elegant than the C# language, supported a syntax of defining and immediately invoking a lambda expression, while the C# language did not support the syntax. This syntax is well known to JavaScript developers as an Immediately Invoked Function Expression, or IIFE.
In this post, I’ll focus on the pipeline solution I devised. Let’s recap the problem I was tasked (ha ha, pun!) with solving:
Technical Constraint: To retrieve the required data, I must call four different web service methods in sequence. The output of each request becomes the input of the next request.
Constraint on Potential Solutions
OK, I can’t merely fire off all HTTP requests at once, let the .NET ThreadPool decide how much network concurrency the computer can support at the moment (via I/O completion ports), wait until all requests have received a response, then assemble the data into a domain class. The problem has a constraint that makes such a fully concurrent solution impossible: the output of one HTTP request becomes the input of the next HTTP request. This forces me to write synchronous code that sequences a method call chain for an individual input value like so:
Input Value -> Method1(input1) -> output1 -> Method2(output1) -> output2 -> Method3(output2) ->
output3 -> Method4(output3) -> Final Value
The above describes a technical constraint on potential solutions to the problem. Let’s not overlook the business constraint on solutions, which is the real driver here: As far as the business is concerned the intermediate results have no value. Only the final result has value.
Business Constraint: The intermediate results have no value. Only the final result has value.
So we understand the business motivation- get the correct data quickly. And we understand a portion of the solution must be written with synchronous code that, given an input value, chains method calls together to produce a final value. Knowing this, can we structure our solution such that many sets of these chained method calls are “in flight” at the same time? That is, can we run multiple method chains concurrently? And can we do this asynchronously? Can our solution avoid blocking while waiting for I/O results, thereby being a good neighbor and allowing other processes running on the computer to leverage threads that otherwise would be trapped in our program doing no effective work?
Ponder the above questions on your own for a while. Sketch out a solution in your mind- or write actual code- then return here when you’re ready to compare solutions.
Version 1 : Fully Sequential Pipeline
I’ll begin by writing a fully sequential solution- the opposite of the fully concurrent solution mentioned above. Whereas we’ve concluded a fully concurrent solution is infeasible, a fully sequential solution is feasible and easy to write. Mine is a naive solution in that it attempts no performance optimizations. Its utility is in…
- Determining the correct final results.
- Establishing baseline performance.
Later, I’ll compare the results and the performance of my async producer / consumer solution to the fully sequential solution.
First, I’ll write an interface that defines a client / service “contract”. As I have done in previous blog posts, I’ll substitute a fictional example (math operations) for the code I wrote for my employer (financial transactions).
Next, I’ll write a web service that implements the interface.
Notice the above code uses Task.Delay to simulate I/O latency of calling a third-party web service over the Internet.
Next, I’ll write a console program that calls the web service. It does this by instantiating an IPipeline interface and invoking the Run method. This enables me to run different versions of pipeline code via a command line switch. The actual HTTP requests are issued by a Refit proxy. In addition, I wrote a cache-busting HTTP message handler that adds a GUID to the URL query string, ensuring the URL of every HTTP request is unique. This prevents subsequent runs of the program from pulling “remembered” results from cache.
Next, I’ll write version 1 of the pipeline code. It calls the math service to perform the following operations in sequence. Both processing of the input value array and processing of each math operation for an individual input value is done sequentially. No code runs concurrently.
- Raise the input value to the 4th power.
- Add 99 to the result.
- Multiply the result by 13.
- Modulo the result by 41. That is, divide the result by 41 and return the remainder.
For example, for an input value of 7:
- 7 Pow 4 = 7 * 7 * 7 * 7 = 2,401.
- 2,401 + 99 = 2,500.
- 2,500 * 13 = 32,500.
- 32,500 % 41 = 28. (32,500 ÷ 41 = 792 with 28 remaining.)
Run version 1 of the pipeline code.
> dotnet run -c release -- 1
Step Values: 4 99 13 41
InputValue Step 1 (Power) Step 2 (Add) Step 3 (Multiply) Step 4 (Modulo)
1 1 100 1,300 29
2 16 115 1,495 19
3 81 180 2,340 3
...
97 88,529,281 88,529,380 1,150,881,940 9
98 92,236,816 92,236,915 1,199,079,895 4
99 96,059,601 96,059,700 1,248,776,100 27
100 100,000,000 100,000,099 1,300,001,287 19
Pipeline ran in 105.188 seconds.
The program takes 105 seconds to call math service methods to calculate the final values for all 100 input values. As you can see in the screen capture below, it issues HTTP requests sequentially. Only a single HTTP request is “in flight” at any given moment.
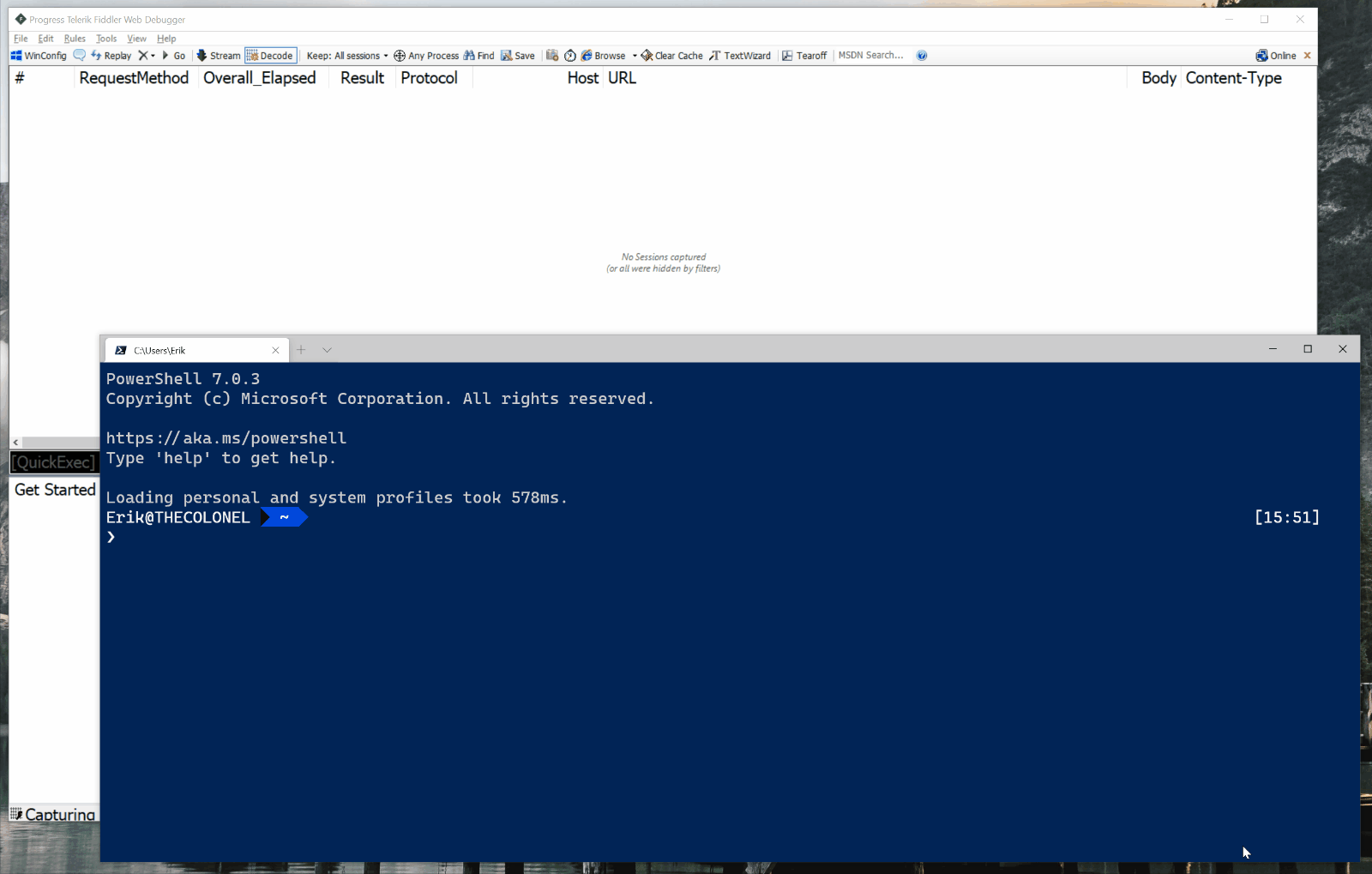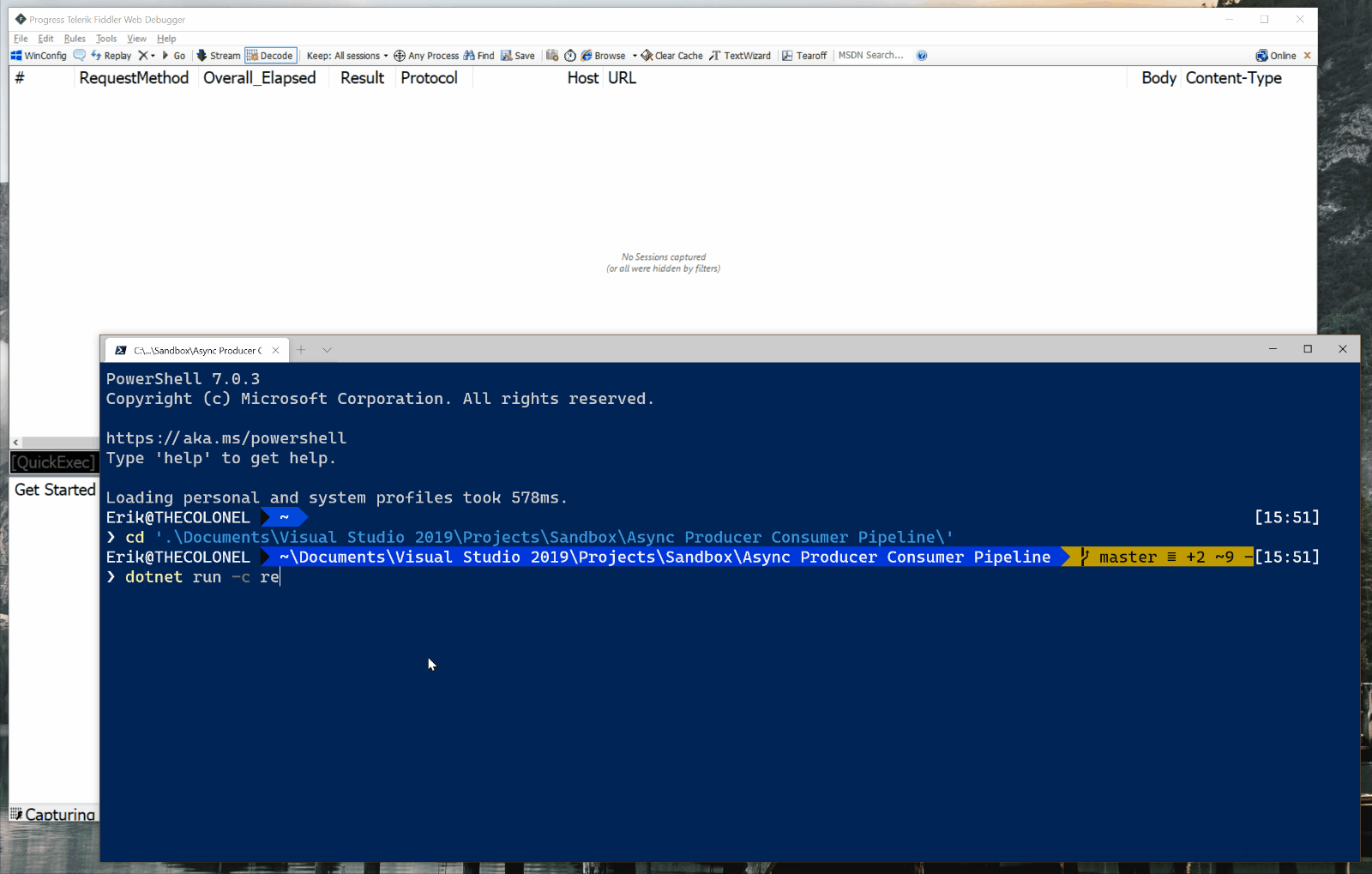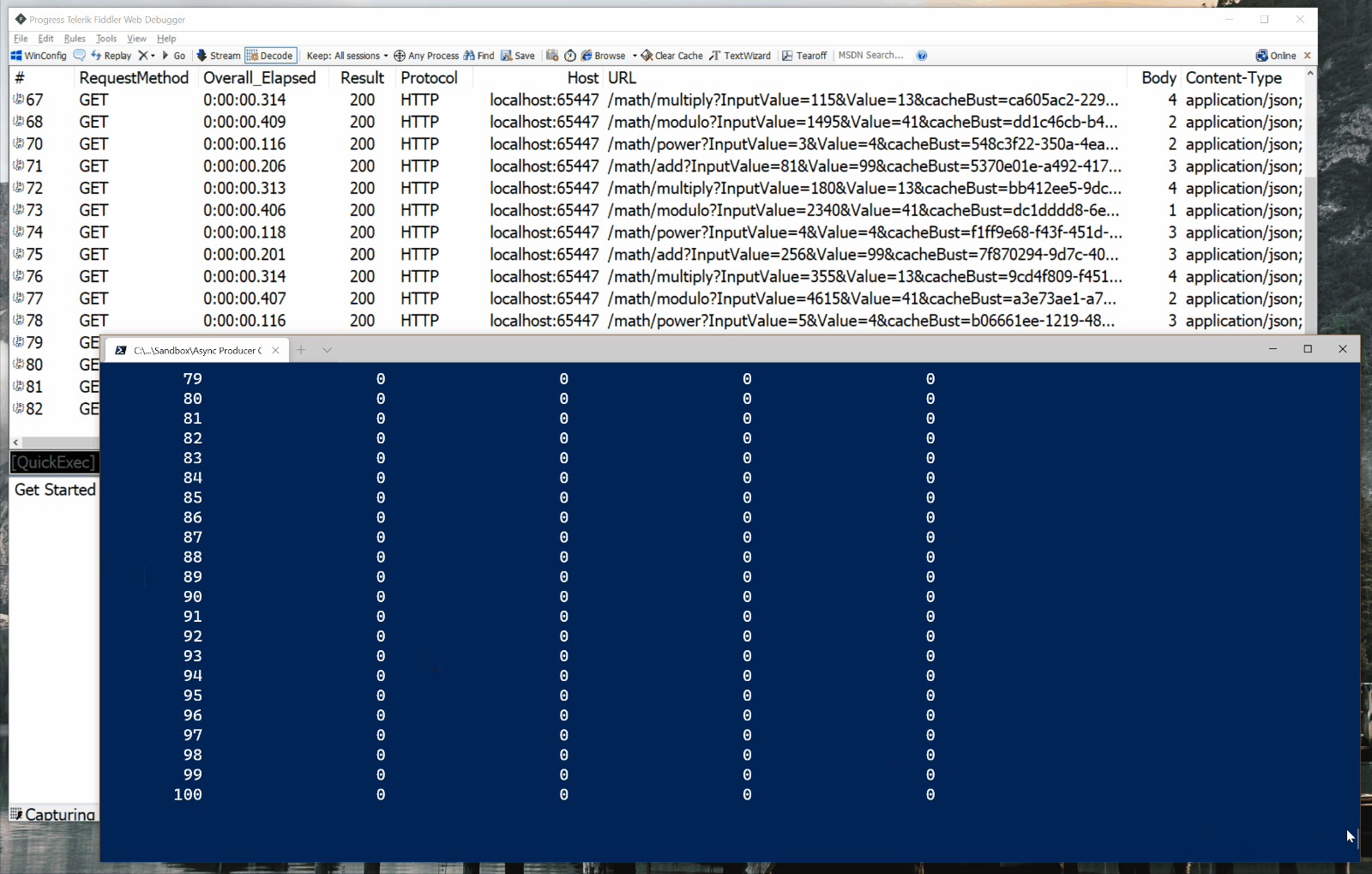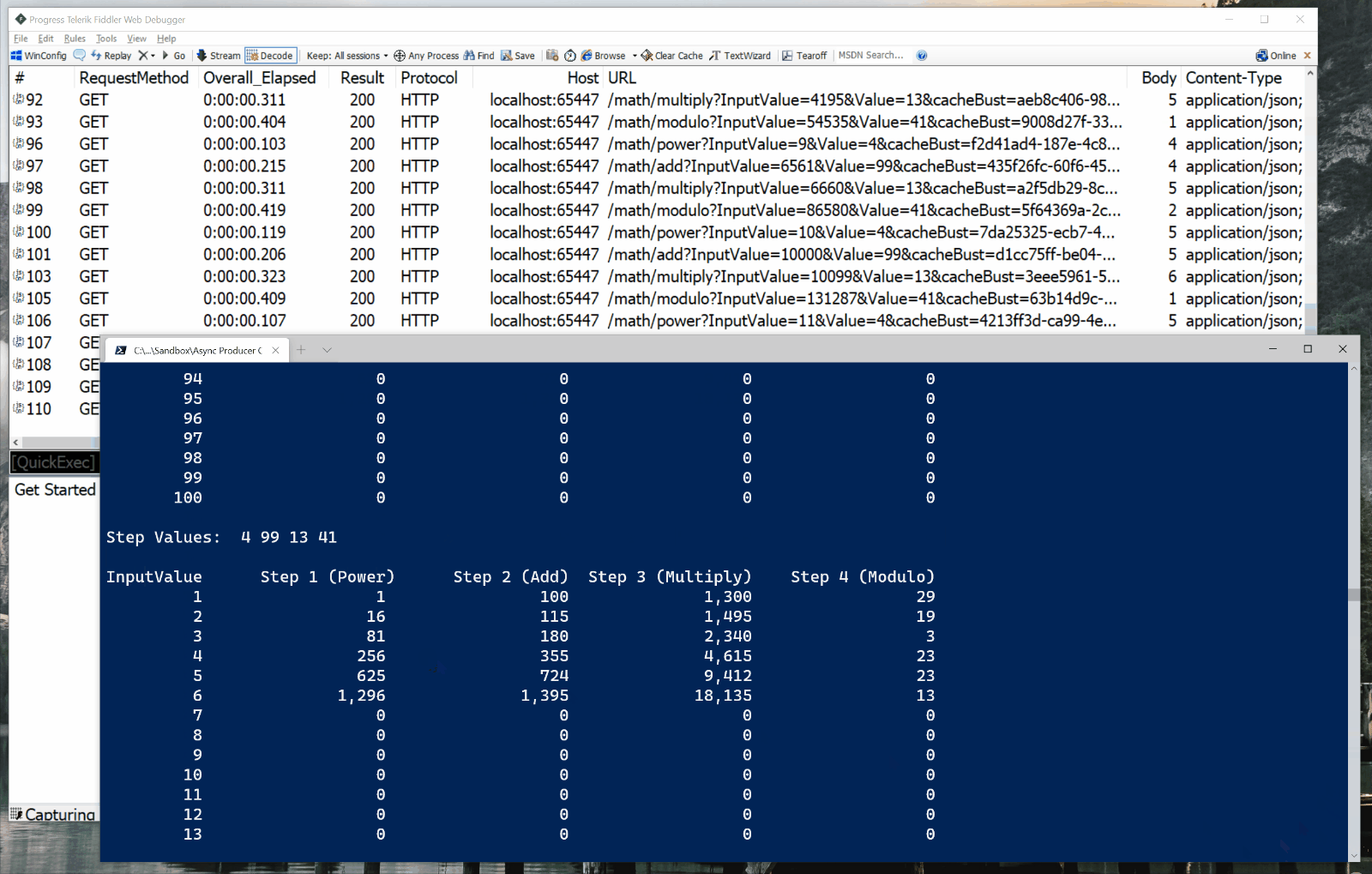
Version 2 : Asynchronous Producer / Consumer Pipeline
How can I improve the performance of this code? I’ll use a producer / consumer pattern. I’ll request all 100 of the IMathService.Power operations concurrently (not waiting for the result of input 1 before requesting input 2), then process results as they arrive. By “process” I mean as the results of operation 1 (Power) arrive, I’ll request the second operation (Add) using the result of operation 1 as the input of operation 2. Similarly, I’ll process results of operation 2 (Add) as they arrive, requesting the third operation (Multiply) using the result of operation 2 as the input of operation 3, etc until I have a final result. This technique requires me to associate an input value with its result at each step of the four step pipeline. I’ll use a Tuple to connect these values.
Notice how a Tuple is returned when awaiting the step 1 task in line 42. HTTP results are not guaranteed to arrive in any well-defined order over a chaotic network such as the Internet, so it’s essential to keep an input value paired with its result. A Tuple is the perfect structure for this and C#’s Tuple Deconstruction syntax provides an elegant way to extract its two values.
One feature of the above code that is critical to reducing the possibility of pernicious multi-threading bugs is while HTTP requests are issued asynchronously, the processing of results is done synchronously (line 41). This eliminates the need to protect non-thread-safe collections with locks or use thread-safe collections.
Run version 2 of the pipeline code.
> dotnet run -c release -- 2
Step Values: 4 99 13 41
InputValue Step 1 (Power) Step 2 (Add) Step 3 (Multiply) Step 4 (Modulo)
1 1 100 1,300 29
2 16 115 1,495 19
3 81 180 2,340 3
...
97 88,529,281 88,529,380 1,150,881,940 9
98 92,236,816 92,236,915 1,199,079,895 4
99 96,059,601 96,059,700 1,248,776,100 27
100 100,000,000 100,000,099 1,300,001,287 19
Pipeline ran in 3.131 seconds.
The program produces the same final results as version 1. However, version 2 takes only 3.1 seconds to call math service methods to calculate the final values for all 100 input values. That’s a 33.6x speedup over version 1!
That’s a 33.6x speedup over version 1!
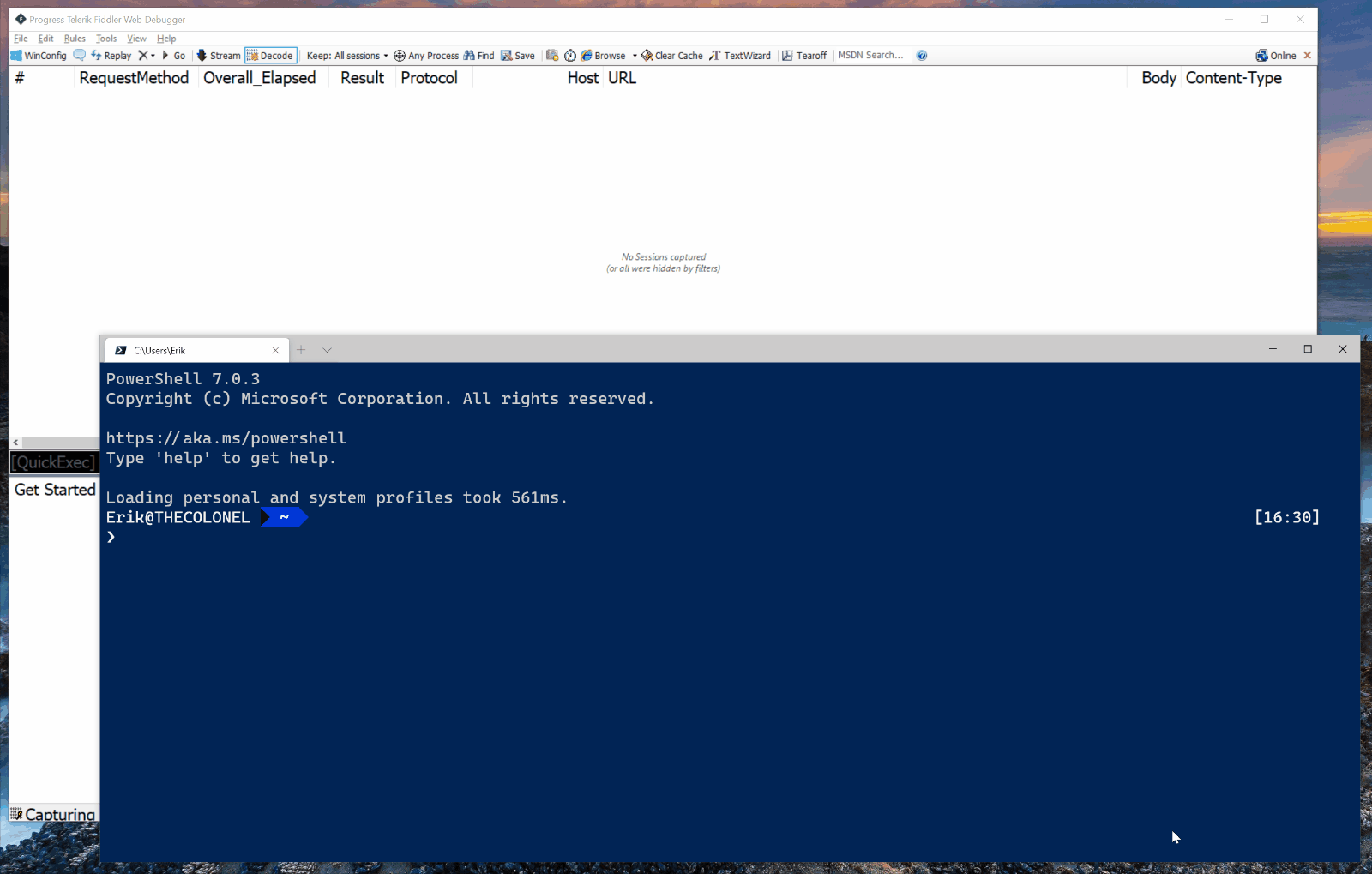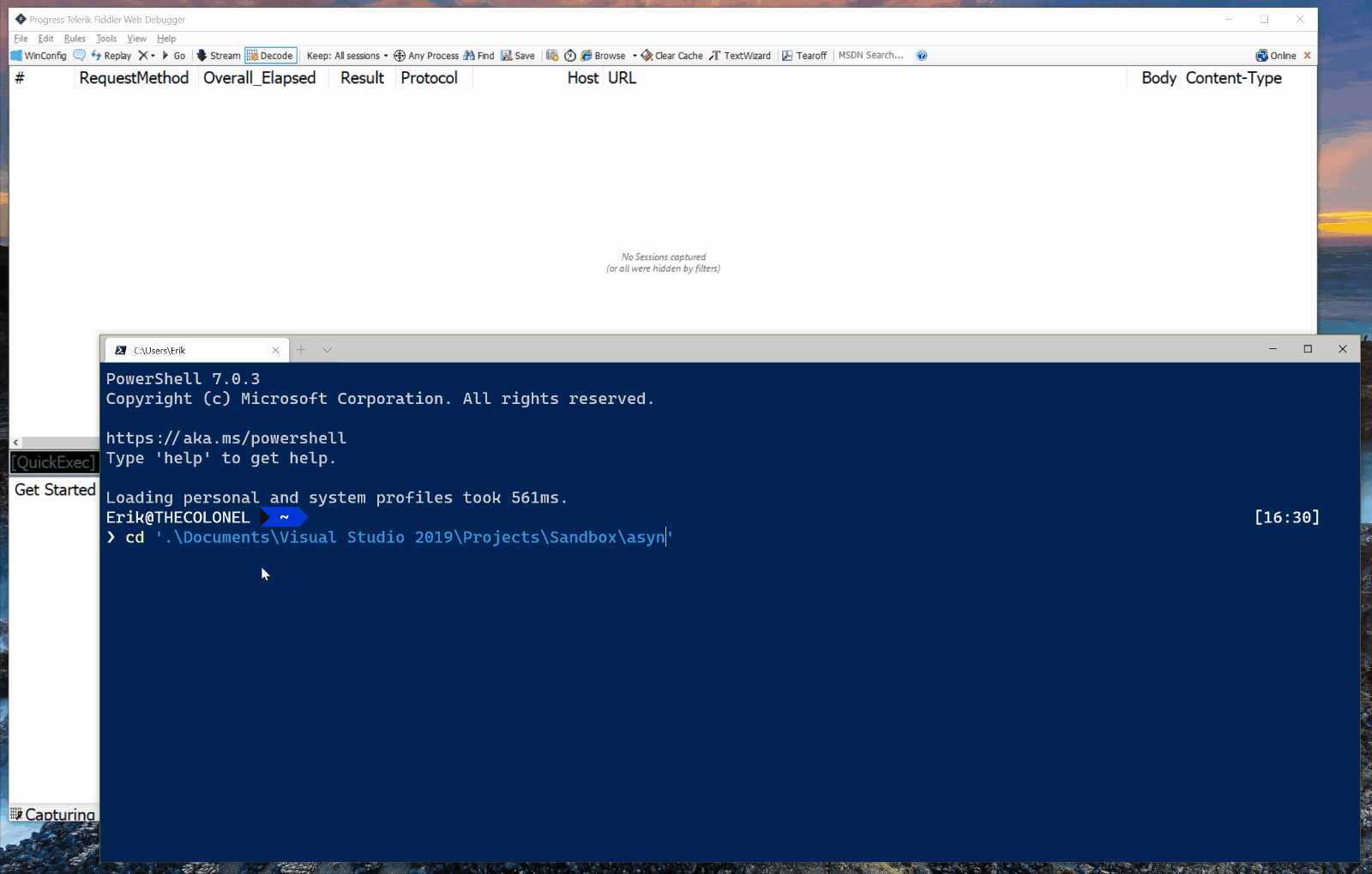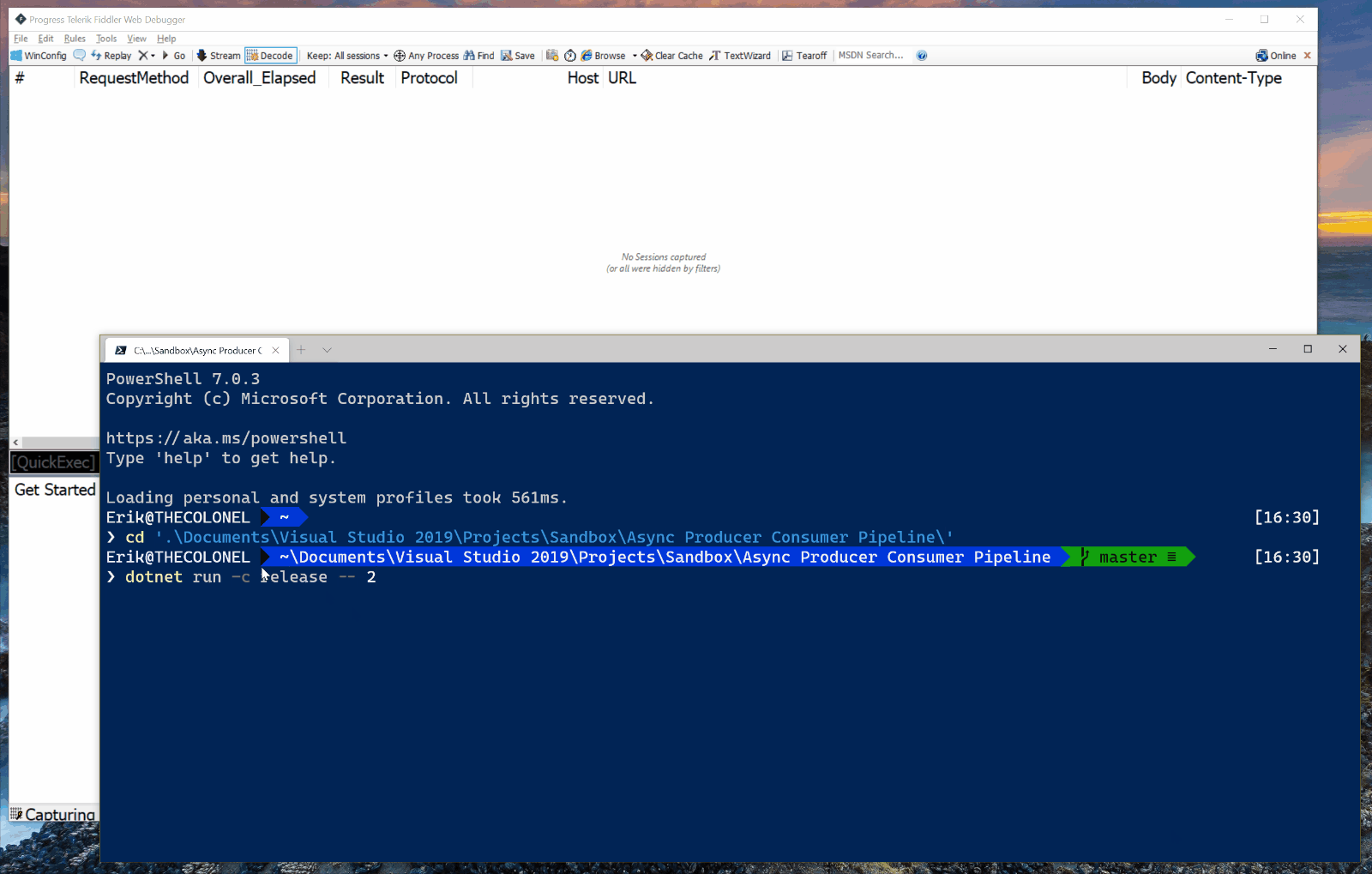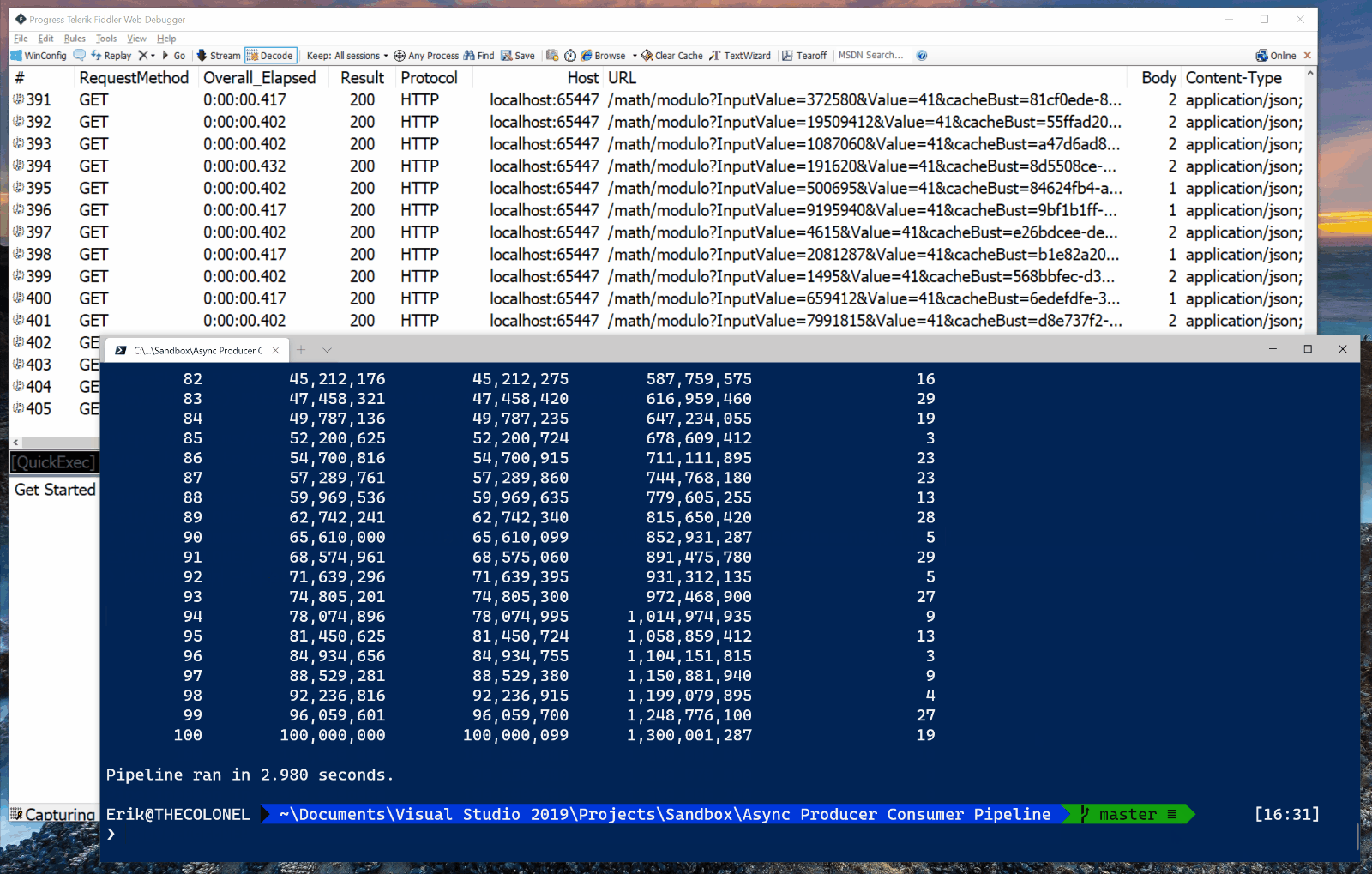
As you can see in the screen capture below, it issues multiple HTTP requests concurrently. Many HTTP requests are “in flight” at any given moment.
Version 3 : Even More Concurrency
You may have noticed a bottleneck in version 2 of the pipeline code. Due to the sequential processing of results (lines 41 – 52), “in flight” HTTP requests are limited to at most two steps concurrently. It’s not possible for the code to issue a step 3 HTTP request until all step 1 results have been processed. Similarly, it cannot issue a step 4 HTTP request until all step 1 and step 2 results have been processed. The “consumer” code can never advance more than two steps ahead of the “producer” code.
Is it possible to improve the code so both requests and results are issued / processed asynchronously? Yes. Does it improve performance? No, not in my experience. I played around with adjusting the Task.Delay code that simulates I/O latency (making early steps faster or slower than later steps) but could not find any performance benefit over version 2. If you’re curious, you may review the “even more concurrency” version 3 of the pipeline code in the Async Producer Consumer Pipeline folder in my Sandbox Github repository.
My recommendation when facing a requirement to call hundreds or thousands of web service methods, constrained by a need to chain subsets of calls in a specific sequence, is to use the technique illustrated in version 2 of my asynchronous producer / consumer pipeline code. If you’re working on web service integration code, and suspect you could benefit from asynchronicity and concurrency, I hope you found my blog post helpful.
